Index
Steeds meer organisaties willen hun chatbot ook aan het telefoniekanaal ontsluiten. Een goede speech-to-text engine (STT-engine) maakt daarbij het verschil tussen een prettige, snelle klantervaring of frustrerende misverstanden. Maar welke engine werkt het beste… en wanneer?
Omdat de prestaties van STT-engines sterk verschillen per taal en per soort input, zijn wij begonnen met een continu benchmark-onderzoek. Dit is een eerste update: een inzicht in wat vandaag werkt, maar ook waar we de komende tijd juist nog aanscherpingen moeten doen.
Waarom dit onderzoek belangrijk is voor voice-oplossingen
Een STT-engine bepaalt de kwaliteit van de voice-oplossing. De verschillen tussen de engines zijn echter groot. Niet alleen zit er verschil in de herkenning per taal, maar ook het type input wordt door engines op verschillende manieren geïnterpreteerd en verwerkt.
Een engine die uitstekend scoort op het interpreteren van postcodes, doet het soms juist slechter op het herkennen van datums. Voor veel organisaties is dat waar het misgaat bij het succesvol inzetten van een voice-oplossing. Welke STT-engine het beste past, hangt namelijk sterk af van de use case.
We willen organisaties daarom een holistisch beeld geven en hen niet laten kiezen op basis van aannames. We bouwen aan een eigen dataset, testen continu en analyseren de resultaten van verschillende STT-engines zelf. Zo krijgen we helder:
- Welke engine het beste scoort per taal
- Welke inputtypes gevoeliger zijn voor fouten
- Waar post-processing binnen Seamly nog beter moet
- Hoe snel engines verbeteren wanneer ze nieuwe modellen uitrollen
- Waar Seamly’s eigen logica de uiteindelijke output verbetert
Seamly optimaliseert spraakherkenning niet eenmalig, maar continu. We analyseren steeds welke STT-engine het beste presteert per taal en per type input. Vervolgens gaan we een stap verder: ons platform verbetert die output door normalisatie, contextlogica en conversatiespecifieke verwerking toe te passen. Hierdoor wordt spraakherkenning omgezet in consistente en direct bruikbare data.
Dat vormt het verschil tussen een transcriptie die ‘ongeveer goed’ is en een voice-dialoog die feitelijk klopt en direct inzetbaar is in telefonische klantinteracties.
Denk bijvoorbeeld aan het herkennen en correct interpreteren van postcodes, nummers, datums en tijden, inclusief de manier waarop mensen die in het dagelijks leven nu eenmaal uitspreken. Op die manier wordt elke STT-engine niet alleen beoordeeld, maar ook optimaal ingezet in real-life belscenario’s.
Hoe testen we verschillende STT-engines?
We testen met 20 standaardzinnen, ingesproken door mensen voor wie de taal hun moedertaal is. Het zijn geen studio opnamens, maar audio in telefoonkwaliteit, zodat het zo dicht mogelijk bij echte telefoongesprekken ligt. Elke opname controleren we handmatig op kwaliteit, zodat we geen ruis in de dataset krijgen.
De dataset is nog beperkt en resultaten zijn daardoor niet volledig generaliseerbaar en reproduceerbaar buiten de context van ons platform. We willen hiermee vooral een sterk startpunt maken voor verder onderzoek.
Wel blijft deze dataset continu groeien. We analyseren nieuwe talen, nieuwe variaties, gebruiken nieuwe stemmen en voegen nieuwe STT-engines toe. We testen dus niet alleen de bekendere engines zoals Azure en Google, maar ook nieuwere spelers zoals OpenAI Mini Transcribe en ElevenLabs Scribe.
Een analyse langs twee assen: taal en inputtype
We bekijken de prestaties op twee verschillende assen:
- Per taal. Nederlandse input gedraagt zich anders dan Engels, en dat geldt ook voor accenten binnen een taal.
- Per inputtype. Denk bijvoorbeeld aan getallen, adressen, postcodes, data en tijden.
Binnen deze twee assen meten we twee kernstatistieken:
- De ‘correctness’: hoeveel tekstuele output klopt exact met de ingesproken input van de beller?
- De ‘word error rate (WER)’: hoeveel woorden moeten we aanpassen om de tekstuele output exact te laten matchen met de input van de beller?
We analyseren zowel de ruwe STT-output van de engines als de output nadat Seamly er pre- en post-processing op heeft toegepast. Bedenk dat ‘overmorgen’ moet worden omgezet naar een bepaalde datum, of dat een postcode uitgesproken als ‘4224 Karel Bernard’ moet worden omgezet naar 4224 KB.
Zo zien we niet alleen hoe goed de spraakherkenning werkt, maar ook waar onze normalisatie en verwerkingstechniek nog verder kan worden aangescherpt voor optimale herkenning in telefonie-omgevingen.
Wat laten de resultaten zien?
Vanaf oktober 2025 meten, vergelijken en analyseren we de prestaties van verschillende STT-engines. Voor dit onderzoek focussen we ons op de Nederlandse en Engelse taal.
Nederlands
Voor het Nederlands scoort Azure momenteel het beste van de verschillende STT-engines. Zo is Azure in 72% van de gevallen correct. Anders gezegd: in 72% van de gevallen klopt de tekstuele output exact met de input van de beller. Ook heeft Azure de laagste word error rate: 18% van de woorden moeten worden aangepast om de output te matchen met de input. Bij OpenAI Transcribe en OpenAI Mini Transcribe ligt de WER een stuk hoger: tussen de 70% en ruim boven de 90%.
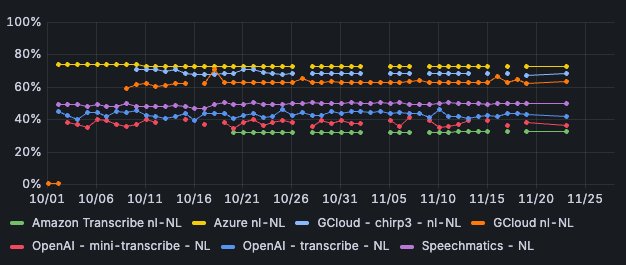
Afbeelding 1: Correctness per STT-engine - Nederlands
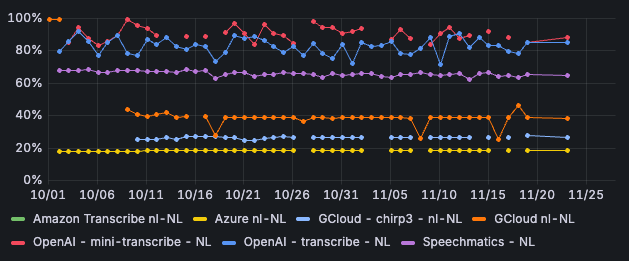
Afbeelding 2: Word error rate per STT-engine - Nederlands
Azure is opvallend sterk in het verwerken van postcodes: in 94% van de gevallen is er een match tussen de input en de output. De engines van OpenAI scoren beduidend lager: In ongeveer 18% van de gevallen worden postcodes maar goed verwerkt.
In het verwerken van alfanumerieke tekens scoren Azure en Chirp3 goed: beide scoren 59% op correctness. Andere engines scoren vaak nog geen 10% op correctness.
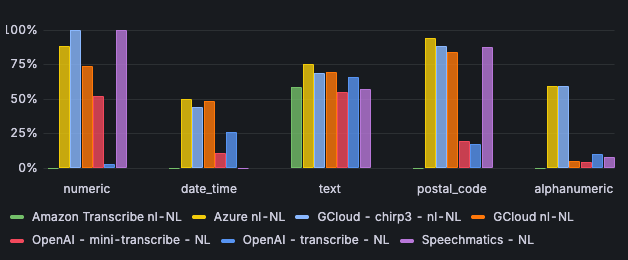
Afbeelding 3: Correctness per input type - Nederlands
Engels
Chirp3 van Google scoort voor het Engels het beste, met een correctness van iets meer dan 73%. Ook scoort deze engine het beste als we de word error rate bekijken: in 12% van de gevallen moeten de woorden worden aangepast om de input met de output te laten matchen.
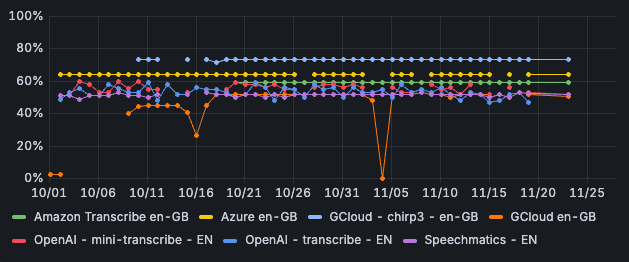
Afbeelding 4: Correctness per STT-engine - Engels
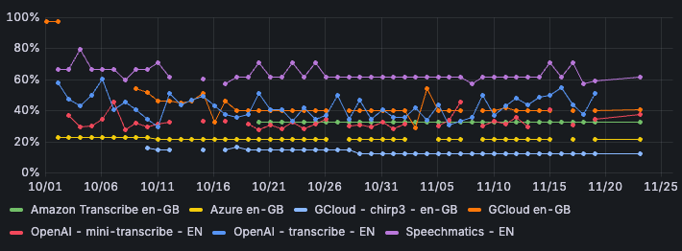
Afbeelding 5: word error rate per STT-engine - Engels
Ook is Google’s Chirp3 het sterkste in het verwerken van datums en tijden met een correctness van 100%. Azure volgt met een correctness van ruim 89%.
Voor het Engels scoren alle engines goed op het verwerken van postcodes, behalve Speechmatics. Daar is de correctness slechts 23%.
Wat betreft het verwerken van alfanumerieke tekens zijn er grote verschillen tussen de engines. Chirp3 en Amazon Scribe scoren 75% op correctness, Azure 47%, OpenAI Transcribe 35% en OpenAI Mini Transcribe slechts 19%.
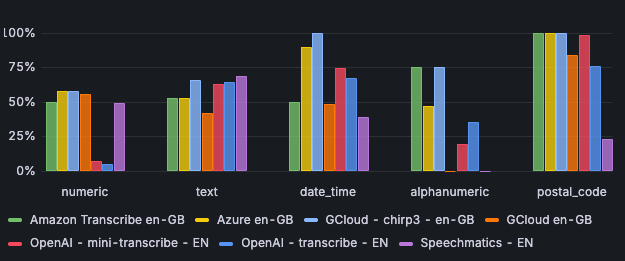
Afbeelding 6: correctness per input type - Engels
Zoals eerder benoemd, tonen we in deze analyse de resultaten na verwerking door Seamly. Met name postcodes, datums en nummers normaliseren we zodat de resultaten eerlijk en eenduidig te vergelijken zijn. Daarbij verschilt de manier waarop engines hun output aanleveren, wat soms tot afwijkingen kan leiden.
Zo kan Google Chirp3 op onderdelen ogenschijnlijk lager scoren dan Azure, terwijl het verschil vooral zit in de vorm van de output die Seamly nog niet volledig normaliseert. Niet alle variaties kunnen we op dit moment al volledig gelijk trekken, waardoor een engine in bepaalde gevallen lager lijkt te scoren dan in werkelijkheid het geval is. De resultaten van de input types numeriek, datums en tijden, alfanumeriek en postcodes kunnen daarom niet los worden gezien van de context van het Seamly platform.
De verschillen laten in ieder geval goed zien dat er niet zoiets bestaat als ‘de beste STT-engine’. Het hangt af van de taal, de input en het soort gesprekken dat de voicebot moet voeren.
Waar gebruiken we deze inzichten voor?
De resultaten gebruiken we direct in lopende voice-implementaties bij partners en klanten. Denk aan het adviseren van de juiste engine per taal en use case, maar ook aan continue finetuning en het delen van nieuwe inzichten. Nieuwe engines testen we eerst uitgebreid binnen het Seamly-platform, zodat we kunnen garanderen dat ze betrouwbaar presteren in echte klantgesprekken via telefonie.
Door structureel te analyseren, ontdekken we daarnaast waar Seamly’s eigen logica en normalisatie verbeterd moet worden. En we houden bij wanneer engines hun modellen verbeteren of aanpassen, waardoor partners en klanten altijd kunnen vertrouwen op actuele, datagedreven inzichten, zonder dat ze zelf uitgebreide STT-analyses hoeven uit te voeren.
Een belangrijke stap vooruit in STT beoordelingen
Dit project zorgt voor een belangrijke stap vooruit in hoe we spraakherkenning beoordelen binnen realistische voice-omgevingen. Tot nu toe was er weinig onderzoek naar hoe STT-engines zich gedragen op telefoonkwaliteit, in meerdere talen, en met input zoals postcodes, data en cijfers. Veel organisaties kozen daardoor op basis van reputatie, niet op basis van harde data.
Met onze analyses brengen we daar verandering in. We creëren een dataset die steeds groter en representatiever wordt. Dat levert inzichten op die de markt tot nu toe miste.
Meer weten?
Met continu benchmark-onderzoek zorgen we ervoor dat voicebots via Seamly altijd worden aangesloten op de STT-engine die het beste past. Dat kan binnenkort ook dynamisch. We laten graag in een demo zien hoe we jouw conversational platform voicificeren, met jouw eigen use case als uitgangspunt.