Index
Liever in het Nederlands lezen?
More and more organizations want to make their chatbot available on the telephone channel as well. A good speech-to-text engine (STT-engine) makes the difference between a pleasant, fast customer experience and frustrating misunderstandings. But which engine works best... and when?
Because the performance of STT-engines varies greatly depending on the language and type of input, we have started conducting continuous benchmark research. This is our first update: an insight into what works today, but also where we need to make improvements in the near future.
Why this research is important for voice solutions
An STT-engine determines the quality of the voice solution. However, there are significant differences between engines. Not only is there a difference in recognition per language, but the type of input is also interpreted and processed differently by engines.
An engine that scores excellently at interpreting postal codes sometimes performs less well at recognizing dates. For many organizations, this is where the successful implementation of a voice solution goes wrong. Which STT-engine is best suited depends heavily on the use case.
We therefore want to give organizations a holistic picture and not let them make choices based on assumptions. We are building our own dataset, continuously testing and analyzing the results of various STT-engines ourselves. This gives us a clear picture of:
- Which engine performs best for each language
- Which input types are more prone to errors
- Where post-processing within Seamly needs improvement
- How quickly engines improve when new models are rolled out
- Where Seamly's own logic improves the final output
Seamly optimizes speech recognition not just once, but continuously. We constantly analyze which STT-engine performs best for each language and type of input. Then we go one step further: our platform improves that output by applying normalization, context logic, and conversation-specific processing. This converts speech recognition into consistent and immediately usable data.
That is the difference between a transcription that is “roughly correct” and a voice dialogue that is factually accurate and can be used immediately in telephone customer interactions.
Consider, for example, the recognition and correct interpretation of postal codes, numbers, dates, and times, including the way people pronounce them in everyday life. In this way, each STT-engine is not only evaluated but also optimally deployed in real-life call scenarios.
How do we test different STT-engines?
We test with 20 standard sentences, spoken by native speakers. These are not studio recordings, but telephone-quality audio, so that they are as close as possible to real telephone conversations. We manually check the quality of each recording to ensure that there is no noise in the dataset.
The dataset is still limited, which means that results cannot be fully generalized and reproduced outside the context of our platform. Our main aim is to create a strong starting point for further research.
However, this dataset continues to grow. We analyze new languages, new variations, use new voices, and add new STT-engines. So we not only test the better-known engines such as Azure and Google, but also newer players such as OpenAI Mini Transcribe and ElevenLabs Scribe.
An analysis along two axes: language and input type
We examine performance on two different axes:
- By language. Dutch input behaves differently than English, and the same applies to accents within a language.
- By input type. Consider, for example, numbers, addresses, postal codes, dates, and times.
Within these two axes, we measure two key statistics:
- The “correctness”: how much of the textual output exactly matches the caller's spoken input?
- The “word error rate (WER)”: how many words do we need to adjust to make the textual output exactly match the caller's input?
We analyze both the raw STT output from the engines and the output after Seamly has applied pre- and post-processing to it. Keep in mind that “the day after tomorrow” must be converted to a specific date, or that a postal code pronounced as “4224 King Bravo” must be converted to 4224 KB.
This allows us to see not only how well speech recognition works, but also where our normalization and processing techniques can be further refined for optimal recognition in telephony environments.
What do the results show?
Starting October 2025, we measure, compare, and analyze the performance of various STT-engines. For this study, we will focus on the Dutch and English languages.
Dutch
Azure currently scores highest among the various STT-engines for Dutch. Azure is correct in 72% of cases. In other words, in 72% of cases, the textual output matches the caller's input exactly. Azure also has the lowest word error rate: 18% of words need to be adjusted to match the output with the input. With OpenAI Transcribe and OpenAI Mini Transcribe, the WER is significantly higher: between 70% and well over 90%.
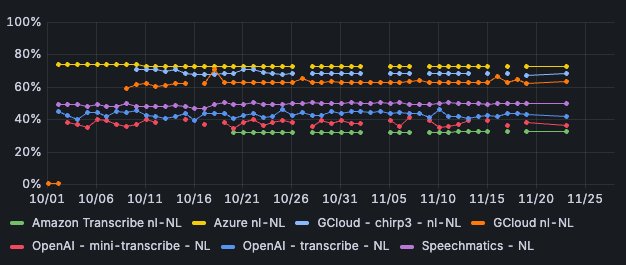
Image 1: Correctness per STT-engine - Dutch
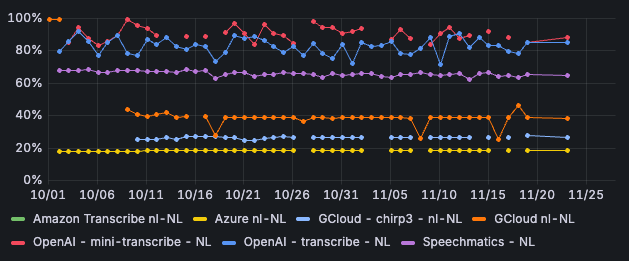
Image 2: Word error rate per STT-engine - Dutch
Azure is remarkably strong at processing postal codes: in 94% of cases, there is a match between the input and the output. OpenAI's engines score significantly lower: in approximately 18% of cases, postal codes are processed correctly.
Azure and Chirp3 perform well in processing alphanumeric characters: both score 59% on correctness. Other engines often score less than 10% on correctness.
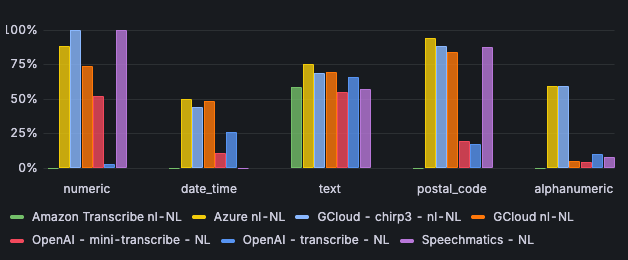
Image 3: Correctness per input type - Dutch
English
Google's Chirp3 scores best for English, with a correctness rate of just over 73%. This engine also scores best when we look at the word error rate: in 12% of cases, the words need to be adjusted to match the input with the output.
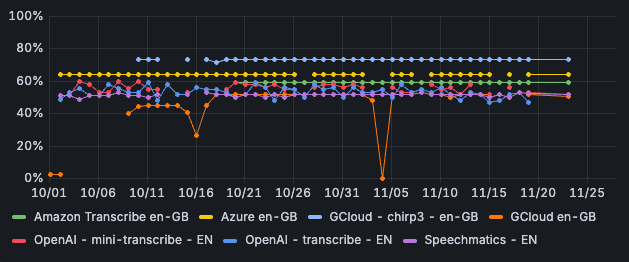
Image 4: Correctness per STT-engine - English
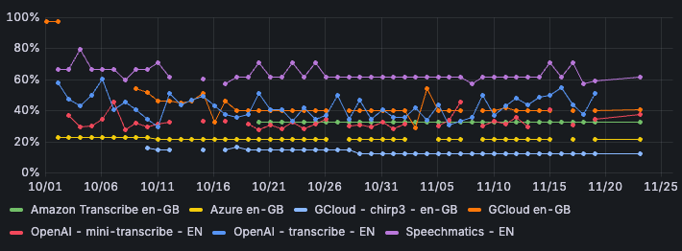
Image 5: word error rate per STT-engine - English
Google's Chirp3 is also the strongest at processing dates and times, with 100% accuracy. Azure follows with an accuracy of over 89%.
For English, all engines score well on processing postal codes, except for Speechmatics, which has an accuracy of only 23%.
When it comes to processing alphanumeric characters, there are significant differences between the engines. Chirp3 and Amazon Scribe score 75% for accuracy, Azure 47%, OpenAI Transcribe 35%, and OpenAI Mini Transcribe only 19%.
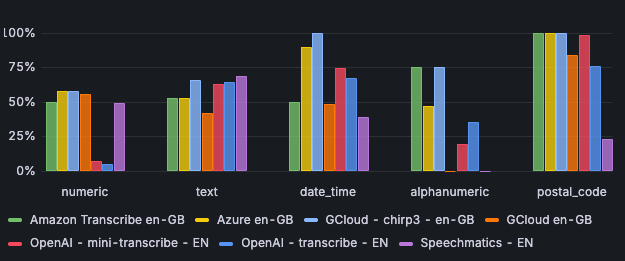
Image 6: correctness per input type - English
As mentioned earlier, this analysis shows the results after processing by Seamly. We normalize postcodes, dates, and numbers in particular so that the results can be compared fairly and unambiguously. The way in which engines deliver their output varies, which can sometimes lead to deviations.
For example, Google Chirp3 may appear to score lower than Azure on certain components, while the difference mainly lies in the form of the output that Seamly does not yet fully normalize. We are not yet able to completely equalize all variations, which means that in certain cases an engine may appear to score lower than it actually does. The results of the input types numeric, dates and times, alphanumeric, and postal codes cannot therefore be viewed separately from the context of the Seamly platform.
In any case, the differences clearly show that there is no such thing as “the best STT-engine.” It depends on the language, the input, and the type of conversations the voicebot needs to conduct.
What do we use these insights for?
We use the results directly in ongoing voice implementations with partners and customers. This includes advising on the right engine for each language and use case, as well as continuous fine-tuning and sharing new insights. We first test new engines extensively within the Seamly platform so that we can guarantee that they perform reliably in real customer conversations via telephone.
Through structural analysis, we also discover where Seamly's own logic and normalization need improvement. And we keep track of when engines improve or adjust their models, so that partners and customers can always rely on up-to-date, data-driven insights without having to perform extensive STT analyses themselves.
An important step forward in STT evaluations
This project represents a significant step forward in how we evaluate speech recognition within realistic voice environments. Until now, there has been little research into how STT-engines perform on telephone-quality audio, in multiple languages, and with input such as postal codes, dates, and numbers. As a result, many organizations have made choices based on reputation rather than hard data.
Our analyses are changing that. We are creating a dataset that is constantly growing and becoming more representative. This provides insights that the market has lacked until now.
Want to know more?
Through continuous benchmark research, we ensure that voicebots via Seamly are always connected to the STT-engine that suits them best. Soon, this will also be possible dynamically. We would be happy to show you in a demo how we can make your conversational platform voice-enabled, based on your own use case.